$ git checkout -b release-1.2 develop Switched to a new branch "release-1.2" $ ./bump-version.sh 1.2 Files modified successfully, version bumped to 1.2. $ git commit -a -m "Bumped version number to 1.2" [release-1.2 74d9424] Bumped version number to 1.2 1 files changed, 1 insertions(+), 1 deletions(-)
$ git checkout -b hotfix-1.2.1 master Switched to a new branch "hotfix-1.2.1" $ ./bump-version.sh 1.2.1 Files modified successfully, version bumped to 1.2.1. $ git commit -a -m "Bumped version number to 1.2.1" [hotfix-1.2.1 41e61bb] Bumped version number to 1.2.1 1 files changed, 1 insertions(+), 1 deletions(-)
分支关闭的时侯不要忘了更新版本号(bump the version) 然后,修复bug,一次提交或者多次分开提交。
1 2 3
$ git commit -m "Fixed severe production problem" [hotfix-1.2.1 abbe5d6] Fixed severe production problem 5 files changed, 32 insertions(+), 17 deletions(-)
if (this.enableDefaultSerializer && defaultUsed) { Assert.notNull(this.defaultSerializer, "default serializer null and not all serializers initialized"); }
if (this.scriptExecutor == null) { this.scriptExecutor = newDefaultScriptExecutor(this); }
@Nullable public <T> T execute(RedisCallback<T> action, boolean exposeConnection, boolean pipeline) { Assert.isTrue(this.initialized, "template not initialized; call afterPropertiesSet() before using it"); Assert.notNull(action, "Callback object must not be null"); RedisConnectionFactoryfactory=this.getRequiredConnectionFactory(); RedisConnectionconn=null;
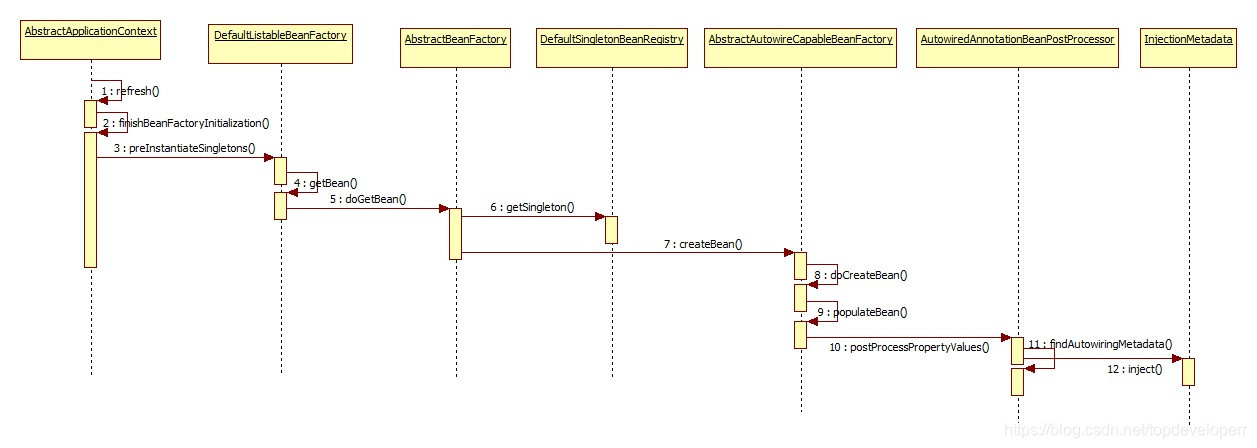
/** * Either this or {@link #getResourceToInject} needs to be overridden. */ protectedvoidinject(Object target, @Nullable String requestingBeanName, @Nullable PropertyValues pvs) throws Throwable {
再来看看 Eureka 集群的工作原理。我们假设有三台 Eureka Server 组成的集群,第一台 Eureka Server 在北京机房,另外两台 Eureka Server 在深圳和西安机房。这样三台 Eureka Server 就组建成了一个跨区域的高可用集群,只要三个地方的任意一个机房不出现问题,都不会影响整个架构的稳定性。
从图中可以看出 Eureka Server 集群相互之间通过 Replicate 来同步数据,相互之间不区分主节点和从节点,所有的节点都是平等的。在这种架构中,节点通过彼此互相注册来提高可用性,每个节点需要添加一个或多个有效的 serviceUrl 指向其他节点。
如果某台 Eureka Server 宕机,Eureka Client 的请求会自动切换到新的 Eureka Server 节点。当宕机的服务器重新恢复后,Eureka 会再次将其纳入到服务器集群管理之中。当节点开始接受客户端请求时,所有的操作都会进行节点间复制,将请求复制到其它 Eureka Server 当前所知的所有节点中。
另外 Eureka Server 的同步遵循着一个非常简单的原则:只要有一条边将节点连接,就可以进行信息传播与同步。所以,如果存在多个节点,只需要将节点之间两两连接起来形成通路,那么其它注册中心都可以共享信息。每个 Eureka Server 同时也是 Eureka Client,多个 Eureka Server 之间通过 P2P 的方式完成服务注册表的同步。
Eureka Server 集群之间的状态是采用异步方式同步的,所以不保证节点间的状态一定是一致的,不过基本能保证最终状态是一致的。
Eureka 分区 Eureka 提供了 Region 和 Zone 两个概念来进行分区,这两个概念均来自于亚马逊的 AWS:
zone:可以简单理解为 region 内的具体机房,比如说 region 划分为深圳,然后深圳有两个机房,就可以在此 region 之下划分出 zone1、zone2 两个 zone。
上图中的 us-east-1c、us-east-1d、us-east-1e 就代表了不同的 Zone。Zone 内的 Eureka Client 优先和 Zone 内的 Eureka Server 进行心跳同步,同样调用端优先在 Zone 内的 Eureka Server 获取服务列表,当 Zone 内的 Eureka Server 挂掉之后,才会从别的 Zone 中获取信息。
Eurka 保证 AP
Eureka Server 各个节点都是平等的,几个节点挂掉不会影响正常节点的工作,剩余的节点依然可以提供注册和查询服务。而 Eureka Client 在向某个 Eureka 注册时,如果发现连接失败,则会自动切换至其它节点。只要有一台 Eureka Server 还在,就能保证注册服务可用(保证可用性),只不过查到的信息可能不是最新的(不保证强一致性)。
首先从会话管理凭证来说,第一种方式的会话凭证仅仅是一个 session id,所以只要这个 session id 足够随机,而不是一个自增的数字 id 值,那么其它人就不可能轻易地冒充别人的 session id 进行操作;第二种方式的凭证(ticket)以及第三种方式的凭证(token)都是一个在服务端做了数字签名,和加密处理的串,所以只要密钥不泄露,别人也无法轻易地拿到这个串中的有效信息并对它进行篡改。总之,这三种会话管理方式的凭证本身是比较安全的。
@Service publicclassA { publicA(B b) { } } @Service publicclassB { publicB(A a) { } }
结果:项目启动失败抛出异常BeanCurrentlyInCreationException
1 2 3 4 5
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference? at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.beforeSingletonCreation(DefaultSingletonBeanRegistry.java:339) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:215) at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:318) at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:199)
org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'mytest.TestSpringBean': Unsatisfied dependency expressed through field 'a'; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'a': Unsatisfied dependency expressed through field 'b'; nested exception is org.springframework.beans.factory.UnsatisfiedDependencyException: Error creating bean with name 'b': Unsatisfied dependency expressed through field 'a'; nested exception is org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference?
at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor$AutowiredFieldElement.inject(AutowiredAnnotationBeanPostProcessor.java:596) at org.springframework.beans.factory.annotation.InjectionMetadata.inject(InjectionMetadata.java:90) at org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor.postProcessProperties(AutowiredAnnotationBeanPostProcessor.java:374)
publicclassDefaultSingletonBeanRegistryextendsSimpleAliasRegistryimplementsSingletonBeanRegistry { ... // 从上至下 分表代表这“三级缓存” privatefinal Map<String, Object> singletonObjects = newConcurrentHashMap<>(256); //一级缓存 privatefinal Map<String, Object> earlySingletonObjects = newHashMap<>(16); // 二级缓存 privatefinal Map<String, ObjectFactory<?>> singletonFactories = newHashMap<>(16); // 三级缓存 ... /** Names of beans that are currently in creation. */ // 这个缓存也十分重要:它表示bean创建过程中都会在里面呆着~ // 它在Bean开始创建时放值,创建完成时会将其移出~ privatefinal Set<String> singletonsCurrentlyInCreation = Collections.newSetFromMap(newConcurrentHashMap<>(16));
/** Names of beans that have already been created at least once. */ // 当这个Bean被创建完成后,会标记为这个 注意:这里是set集合 不会重复 // 至少被创建了一次的 都会放进这里~~~~ privatefinal Set<String> alreadyCreated = Collections.newSetFromMap(newConcurrentHashMap<>(256)); }
// 若存在真正依赖,那就报错(不要等到内存移除你才报错,那是非常不友好的) // 这个异常是BeanCurrentlyInCreationException,报错日志也稍微留意一下,方便定位错误~~~~ if (!actualDependentBeans.isEmpty()) { thrownewBeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been " + "wrapped. This means that said other beans do not use the final version of the " + "bean. This is often the result of over-eager type matching - consider using " + "'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example."); } } } } return exposedObject; }
// A@1234依赖的是["b"],所以此处去检查b // 如果最终存在实际依赖的bean:actualDependentBeans不为空 那就抛出异常 证明循环引用了~ for (String dependentBean : dependentBeans) { // 这个判断原则是:如果此时候b并还没有创建好,this.alreadyCreated.contains(beanName)=true表示此bean已经被创建过,就返回false // 若该bean没有在alreadyCreated缓存里,就是说没被创建过(其实只有CreatedForTypeCheckOnly才会是此仓库) if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) { actualDependentBeans.add(dependentBean); } } if (!actualDependentBeans.isEmpty()) { thrownewBeanCurrentlyInCreationException(beanName, "Bean with name '" + beanName + "' has been injected into other beans [" + StringUtils.collectionToCommaDelimitedString(actualDependentBeans) + "] in its raw version as part of a circular reference, but has eventually been " + "wrapped. This means that said other beans do not use the final version of the " + "bean. This is often the result of over-eager type matching - consider using " + "'getBeanNamesOfType' with the 'allowEagerInit' flag turned off, for example."); } } } } }
Caused by: org.springframework.beans.factory.BeanCurrentlyInCreationException: Error creating bean with name 'a': Requested bean is currently in creation: Is there an unresolvable circular reference? at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.beforeSingletonCreation(DefaultSingletonBeanRegistry.java:339) at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:215)
Connected to the target VM, address: '127.0.0.1:53621', transport: 'socket' finalize Disconnected from the target VM, address: '127.0.0.1:53621', transport: 'socket'
Connected to the target VM, address: '127.0.0.1:55151', transport: 'socket' com.cyblogs.java.learning.C001_ReferenceType.M@38cccef null finalize Disconnected from the target VM, address: '127.0.0.1:55151', transport: 'socket'
我们看一下ThreadLocal的set方法:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17
/** * Sets the current thread's copy of this thread-local variable * to the specified value. Most subclasses will have no need to * override this method, relying solely on the {@link #initialValue} * method to set the values of thread-locals. * * @param value the value to be stored in the current thread's copy of * this thread-local. */ publicvoidset(T value) { Threadt= Thread.currentThread(); ThreadLocalMapmap= getMap(t); if (map != null) map.set(this, value); else createMap(t, value); }