淘宝根据自身业务需求研发了TDDL(Taobao Distributed Data Layer)框架,主要用于解决分库分表场景下的访问路由(持久层与数据访问层的配合)以及异构数据库之间的数据同步,它是一个基于集中式配置的JDBC DataSource实现,具有分库分表、Master/Salve、动态数据源配置等功能。
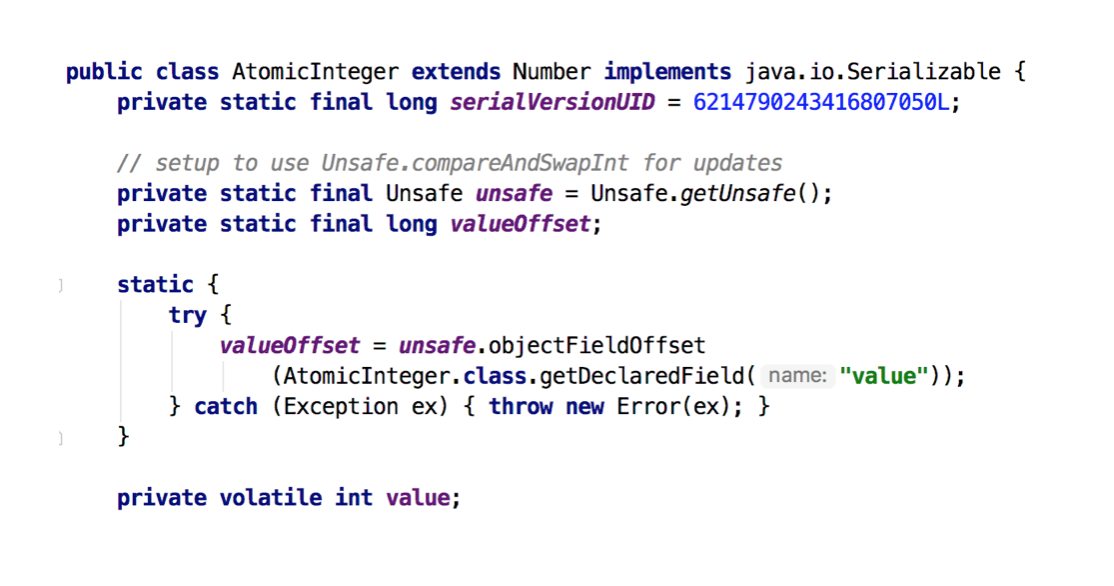
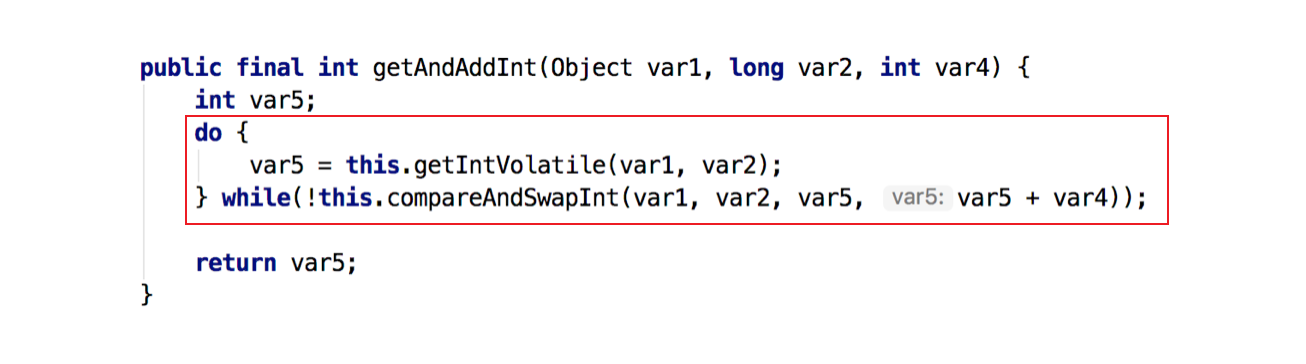
// Unsafe.class publicfinalintgetAndAddInt(Object var1, long var2, int var4) { int var5; do { var5 = this.getIntVolatile(var1, var2); } while(!this.compareAndSwapInt(var1, var2, var5, var5 + var4)); return var5; }
// ------------------------- OpenJDK 8 ------------------------- // Unsafe.java publicfinalintgetAndAddInt(Object o, long offset, int delta) { int v; do { v = getIntVolatile(o, offset); } while (!compareAndSwapInt(o, offset, v, v + delta)); return v; }
根据OpenJDK 8的源码我们可以看出,getAndAddInt()循环获取给定对象o中的偏移量处的值v,然后判断内存值是否等于v。如果相等则将内存值设置为 v + delta,否则返回false,继续循环进行重试,直到设置成功才能退出循环,并且将旧值返回。整个“比较+更新”操作封装在compareAndSwapInt()中,在JNI里是借助于一个CPU指令完成的,属于原子操作,可以保证多个线程都能够看到同一个变量的修改值。
后续JDK通过CPU的cmpxchg指令,去比较寄存器中的 A 和 内存中的值 V。如果相等,就把要写入的新值 B 存入内存中。如果不相等,就将内存值 V 赋值给寄存器中的值 A。然后通过Java代码中的while循环再次调用cmpxchg指令进行重试,直到设置成功为止。
Mark Word:默认存储对象的HashCode,分代年龄和锁标志位信息。这些信息都是与对象自身定义无关的数据,所以Mark Word被设计成一个非固定的数据结构以便在极小的空间内存存储尽量多的数据。它会根据对象的状态复用自己的存储空间,也就是说在运行期间Mark Word里存储的数据会随着锁标志位的变化而变化。
Klass Point:对象指向它的类元数据的指针,虚拟机通过这个指针来确定这个对象是哪个类的实例。
➜ Desktop curl -sSL https://zipkin.io/quickstart.sh | bash -s Thank you for trying Zipkin! This installer is provided as a quick-start helper, so you can try Zipkin out without a lengthy installation process.
Fetching version number of latest io.zipkin:zipkin-server release... Latest release of io.zipkin:zipkin-server seems to be 2.19.2
Downloading io.zipkin:zipkin-server:2.19.2:exec to zipkin.jar...
==> Downloading https://github.com/rabbitmq/rabbitmq-server/releases/download/v3.8.0/rabbitmq-server-generic-unix-3.8.0.tar.xz ==> Downloading from https://github-production-release-asset-2e65be.s3.amazonaws.com/924551/71891480-e44b-11e9-80fd-c06739f04c5e?X-Amz-Algorith ######################################################################## 100.0% ==> /usr/bin/unzip -qq -j /usr/local/Cellar/rabbitmq/3.8.0/plugins/rabbitmq_management-3.8.0.ez rabbitmq_management-3.8.0/priv/www/cli/rabbitmq ==> Caveats Management Plugin enabled by default at http://localhost:15672
Bash completion has been installed to: /usr/local/etc/bash_completion.d
To have launchd start rabbitmq now and restart at login: brew services start rabbitmq Or, if you don't want/need a background service you can just run: rabbitmq-server ==> Summary 🍺 /usr/local/Cellar/rabbitmq/3.8.0: 277 files, 18.2MB, built in 34 seconds ==> `brew cleanup` has not been run in 30 days, running now... Removing: /usr/local/Cellar/jpeg/9b... (20 files, 724KB) Removing: /usr/local/Cellar/libpng/1.6.34... (26 files, 1.2MB) Removing: /usr/local/Cellar/libtiff/4.0.8_5... (245 files, 3.4MB) Removing: /usr/local/Cellar/wxmac/3.0.3.1_1... (810 files, 24.3MB) Removing: /Users/chenyuan/Library/Caches/Homebrew/Cask/minikube--0.25.0... (41.3MB) Removing: /Users/chenyuan/Library/Logs/Homebrew/go... (64B) Removing: /Users/chenyuan/Library/Logs/Homebrew/readline... (64B) Removing: /Users/chenyuan/Library/Logs/Homebrew/sqlite... (64B) Removing: /Users/chenyuan/Library/Logs/Homebrew/kubernetes-cli... (64B) Pruned 0 symbolic links and 2 directories from /usr/local
➜ ~ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 662e8531eb70 centos:7 "/bin/bash" 2 hours ago Up 2 hours 0.0.0.0:33062->3306/tcp docker-mysql-slave c738746e9623 centos:7 "/bin/bash" 4 hours ago Up 4 hours 0.0.0.0:33061->3306/tcp docker-mysql-master
[root@c738746e9623 bin]# ./mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands endwith ; or \g. Your MySQL connection id is2 Server version: 5.6.45-log MySQL Community Server (GPL) mysql>grant replication slave on*.*to'slave_account'@'%' identified by'123456'; Query OK, 0rows affected (0.01 sec) mysql> flush privileges; Query OK, 0rows affected (0.01 sec)








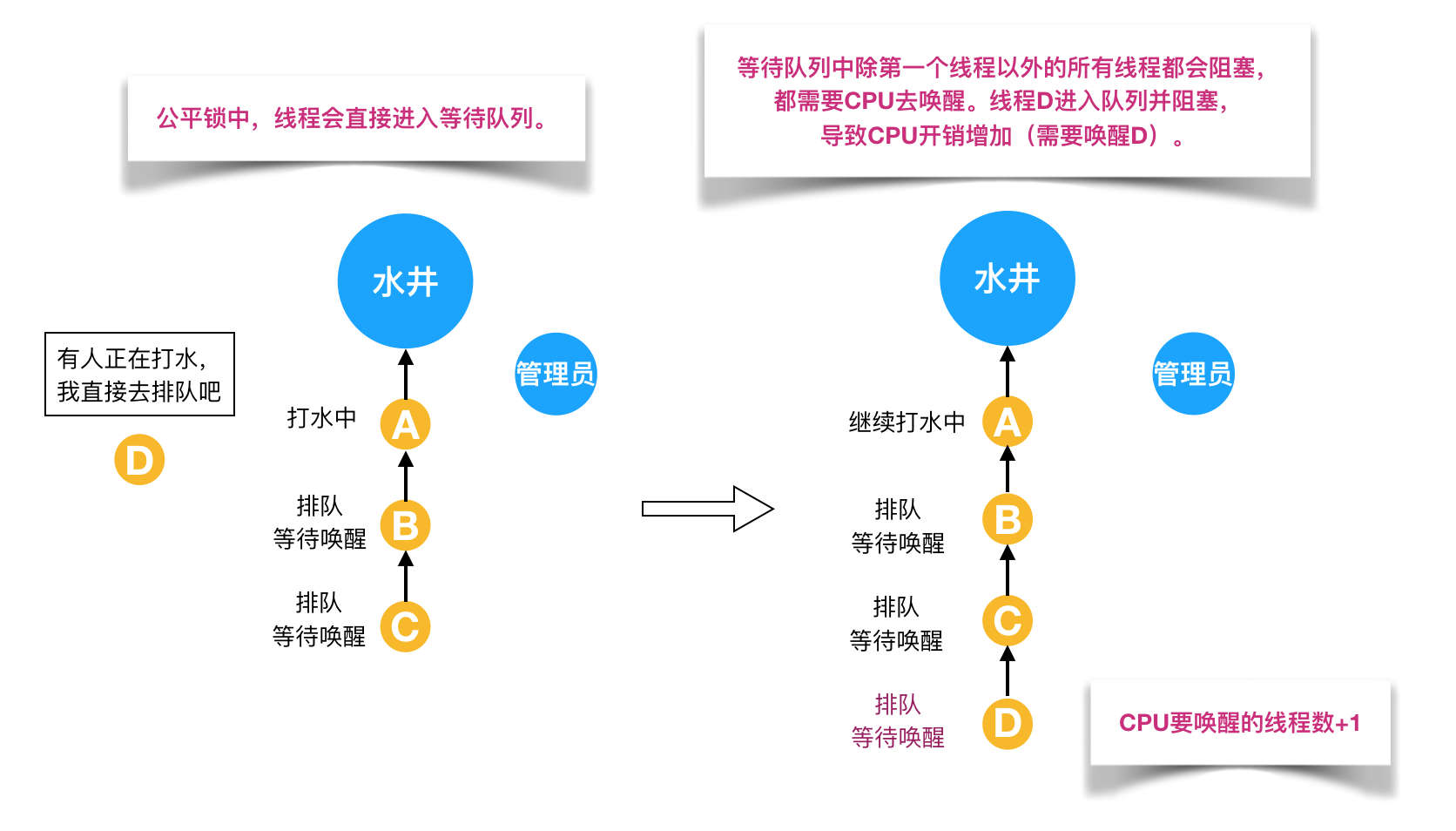
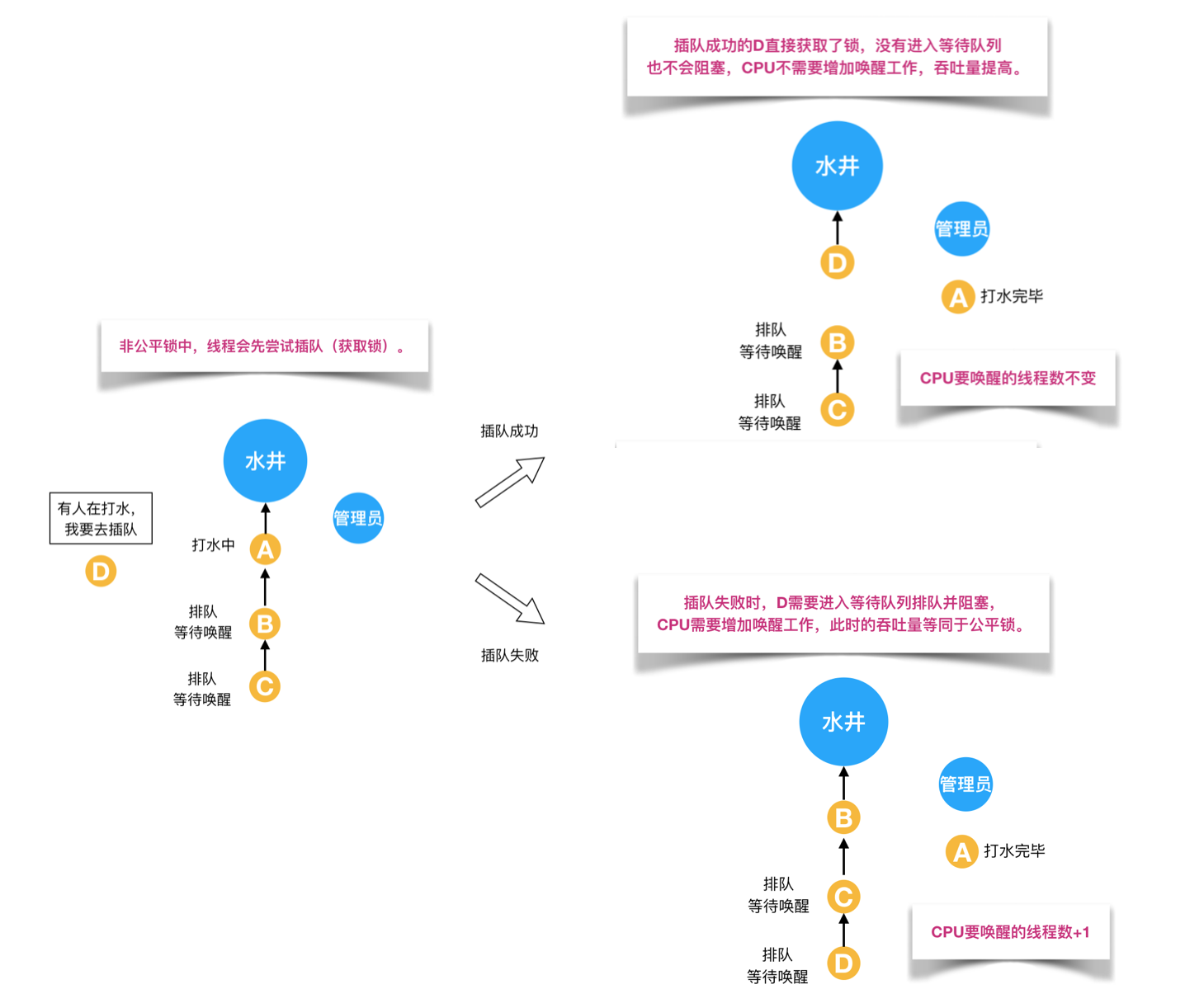
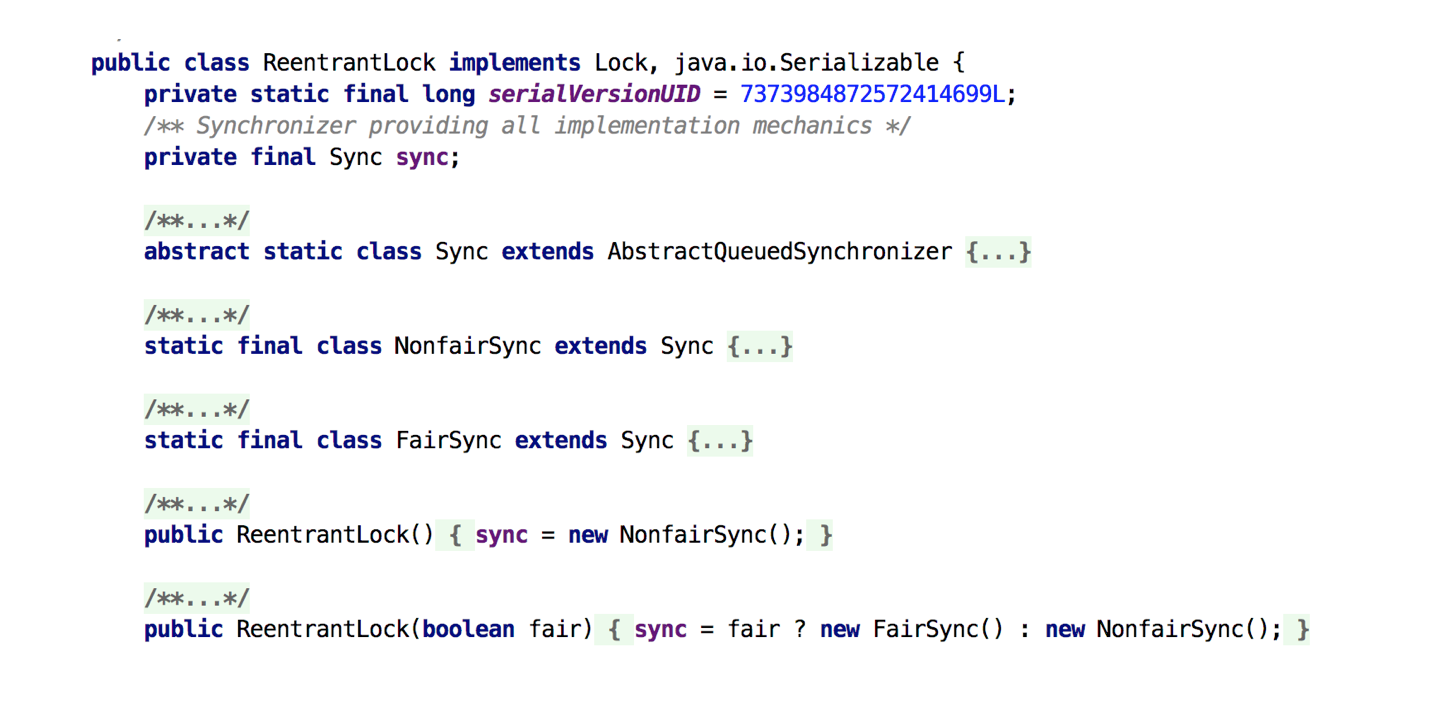


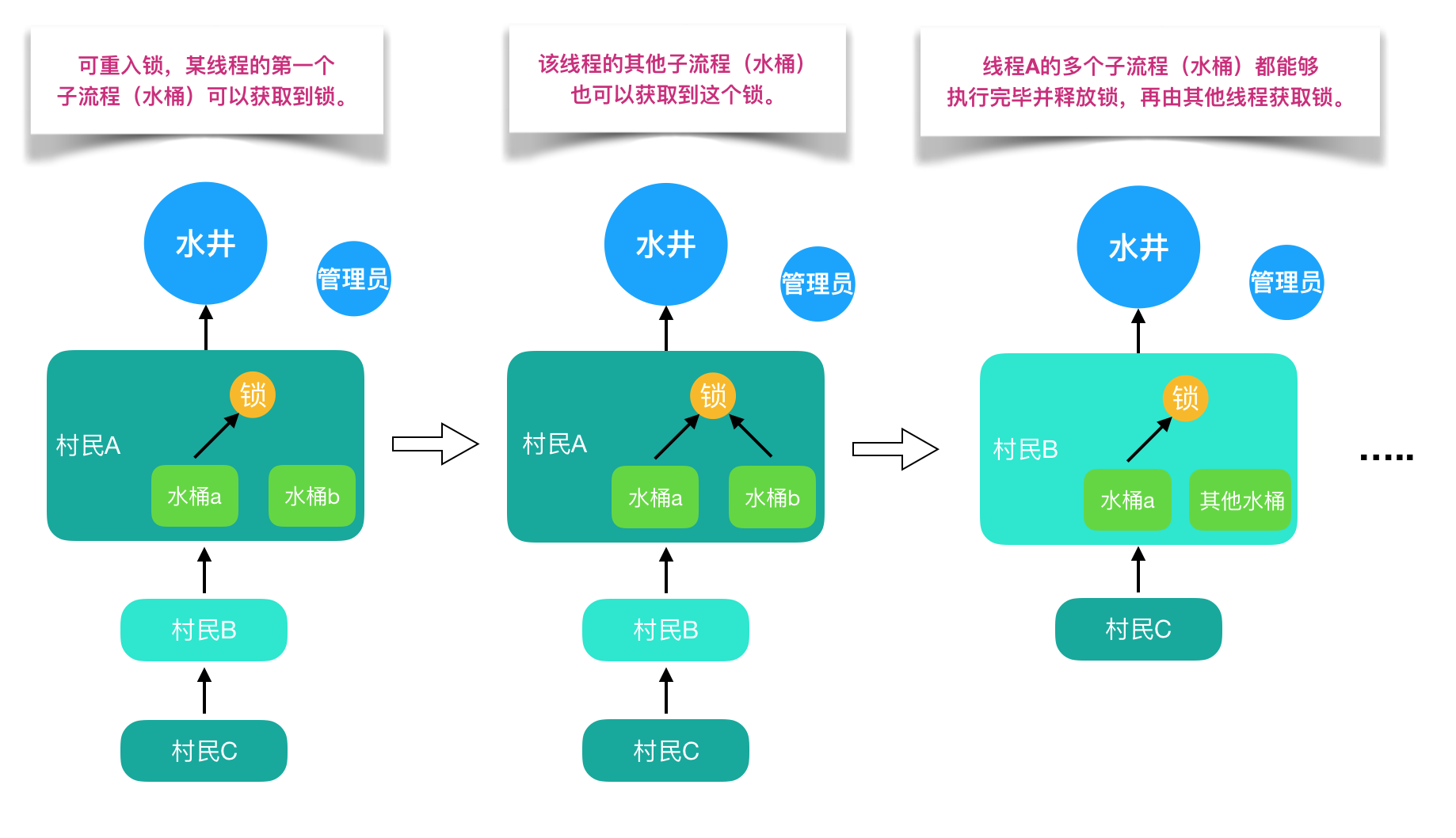










 可配置的环境变量如下表所示:
可配置的环境变量如下表所示:








